Data Security in the SaaS Age: Focus on What You Control
As we launched our series on Data Security in the SaaS Age, we described the challenge of protecting data as it continues to spread across dozens (if not hundreds) of different cloud providers. We also focused attention on the Data Security Triangle, as the best tool we can think of to keep focused on addressing at least one of the underlying prerequisites for a data breach (data, exploit, and exfiltration). If you break any leg of the triangle you stop the breach. The objective of this research is to rethink data security, which requires us to revisit where we’ve been. That brings us back to the Data Security Lifecycle, which we last updated in 2011 in parts one, two and three).
Lifecycle Challenges
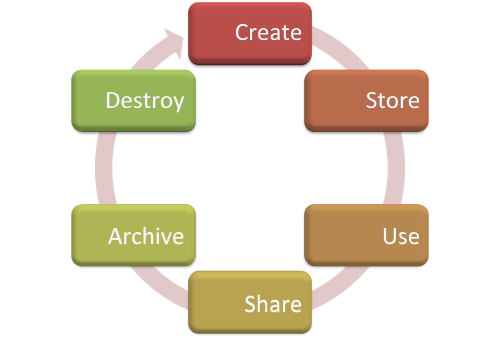 At the highest level, the Data Security Lifecycle lifecycle lays out six phases from creation to destruction. We depict it as a linear progression, but data can bounce between phases without restriction, and need not pass through all stages (for example not all data is eventually destroyed).
At the highest level, the Data Security Lifecycle lifecycle lays out six phases from creation to destruction. We depict it as a linear progression, but data can bounce between phases without restriction, and need not pass through all stages (for example not all data is eventually destroyed).
- Create: This is probably better called Create/Update because it applies to creating or changing a data/content element, not just a document or database. Creation is generating new digital content or altering/updating of existing content.
- Store: Storing is the act committing digital data to some sort of storage repository, and typically occurs nearly simultaneously with creation.
- Use: Data is viewed, processed, or otherwise used in some sort of activity.
- Share: Exchange of data between users, customers, or partners.
- Archive: Data leaves active use and enters long-term storage.
- Destroy: Permanent destruction of data using physical or digital means such as crypto-shredding.
With this lifecycle in mind, you can evaluate data and make decisions about appropriate locations and access. You need to figure out where the data can reside, which controls apply to each possible location, and how to protect data as it moves. Then go through a similar exercise to specify rules for access, determining who can access the data and how. And your data security strategy depends on protecting all critical data, so you need to run through this exercise for every important data type. Then dig another level down to figure out which functions (such as Access, Process, Store) apply to each phase of the lifecycle. Finally, you can determine which controls enable data usage for which functions. Sound complicated? It is, enough that it’s impractical to use this model at scale. That’s why we need to rethink data security. Self-flagellation aside, we can take advantage of the many innovations we’ve seen since 2011 in the areas of application consumption and data provenance. We are building fewer applications and embracing SaaS. For the applications you still build, you leverage cloud storage and other platform services. So data security is not entirely your problem anymore. To be clear, you are still accountable to protect the critical data – that doesn’t change. But you can share responsibility for data security. You set policies but within the framework of what your provider supports. Managing this shared responsibility becomes the most significant change in how we view data security. And we need this firmly in mind when we think about security controls.
Adapting to What You Control
Returning to the Data Breach Triangle, you can stop a breach by either ‘eliminating’ the data to steal, stopping the exploit, or preventing egress/exfiltration. In SaaS you cannot control the exploit, so forget that. You also probably don’t see the traffic going directly to a SaaS provider unless you inefficiently force all traffic through an inspection point. So focusing on egress/exfiltration probably won’t suffice either. That leaves you to control the data. Specifically to prevent access to sensitive data, and restrict usage to authorized parties. If you prevent unauthorized parties from accessing data, it’s tough for them to steal it. If we can ensure that only authorized parties can perform certain functions with data, it’s hard for them to misuse it. And yes – we know this is much easier said than done. Restated, data security in a SaaS world requires much more focus on access and application entitlements. You handle it by managing entitlements at scale. An entitlement ensures the right identity (user, process, or service) can perform the required function at an approved time. Screw this up and you don’t have many chances left to protect your data, because you can’t see the network or control application code. If we dig back into the traditional Data Security Lifecycle, the SaaS provider handles a lot of these functions – including creation, storage, archiving, and destruction. You can indeed extract data from a SaaS provider for backup or migration, but we’re not going there now. We will focus on the Use and Share phases. This isn’t much of a lifecycle anymore, is it? Alas, we should probably relegate the full lifecycle to the dustbin of “it seemed like a good idea at the time.” The modern critical requirements for data security involve setting up data access policies, determining the right level of authorization for each SaaS application, and continuously monitoring and enforcing policies.
The Role of Identity in Data Protection
You may have heard the adage that “Identity is the new perimeter.” Platitudes aside, it’s basically true, and SaaS data security offers a good demonstration. Every data access policy associates with an identity. Authorization policies within SaaS apps depend on identity as well. Your SaaS data security strategy hinges on identity management, like most other things you do in the cloud. This dependency puts a premium on federation because managing hundreds of user lists and handling the provisioning/deprovisioning process individually for each application doesn’t scale. A much more workable plan is to implement an identity broker to interface with your authoritative source and federate identities to each SaaS application. This becomes part of your critical path to provide data security. But that’s a bit afield from this research, so we need to leave it at that.
Data Guardrails and Behavioral Analytics
If managing data security for SaaS applications boils down to being able to set and enforce policies for each SaaS app, your efforts require a clear understanding of each specific application, so you can set appropriate access and authorization policies. Yes, SaaS vendor should make that easy, but in reality… not so much. But setting policies is only the first step. Environments change regularly, as new modules become operational and new users onboard. Policies change frequently, which creates an opportunity for mistakes and attacks. That all brings us to Data Guardrails and Behavioral Analytics. We first introduced this concept back in late 2018. For the backstory, you can take a deep dive into the concept in two parts. But here’s a high-level recap of the concepts:
- Data Guardrails: We see Guardrails as a means of enforcing best practices without slowing down or impacting typical operations. Typically used within the context of cloud security (like, er, DisruptOps), a data guardrail enables data to be used in approved ways while blocking unauthorized use. To bust out an old network security term, you can think of guardrails like “default-deny” for data. You define acceptable practices and don’t allow anything else.
- Data Behavioral Analytics: Many of you have heard of UBA (User Behavioral Analytics), which profiles all user activity and then monitors for anomalous activities which could indicate one of the insider risk categories above. But what if you turned UBA inside out and focused on data? Using similar analytics you could profile all data usage in your environment, and then look for abnormal patterns that warrant investigation.
The key difference is that data guardrails leverage this knowledge with deterministic models and processes to define who can do what and stop everything else. Data behavioral analytics extends the analysis to include current and historical activity, using machine learning algorithms to identify unusual patterns that bypass other data security controls. It’s not an either/or choice, as we figure out how to enforce data security policies in all these SaaS environments. You start by defining data guardrails, which provide you the ability to establish allowed activities in each SaaS application for each user, group, and role. Then you monitor data usage for potentially malicious activities. We favor this approach to dealing with SaaS (and even most cloud-based data usage) because it enables you to focus on what you control. You still think about data through its lifecycle – but your responsibilities within the lifecycle have changed with shared responsibilities. Our next post will dig into how to implement this kind of approach in a SaaS world. To give you a little hint, you’ll need to think small for a huge impact.