DLP Selection Process: Defining the Content
In our last post we kicked off the DLP selection process by putting the team together. Once you have them in place, it’s time to figure out which information you want to protect. This is extremely important, as it defines which content analysis techniques you require, which is at the core of DLP functionality.
This multistep process starts with figuring out your data priorities and ends with your content analysis requirements:
Stack rank your data protection priorities
The first step is to list our which major categories of data/content/information you want to protect. While it’s important to be specific enough for planning purposes, it’s okay to stay fairly high-level. Definitions such as “PCI data”, “engineering plans”, and “customer lists” are good. Overly general categories like “corporate sensitive data” and “classified material” are insufficient – too generic, and they cannot be mapped to specific data types. This list must be prioritized; one good way of developing the ranking is to pull the business unit representatives together and force them to sort and agree to the priorities, rather than having someone who isn’t directly responsible (such as IT or security) determine the ranking.
Define the data type
For each category of content listed in the first step, define the data type, so you can map it to your content analysis requirements:
Structured or patterned data is content like credit card numbers, Social Security Numbers, and account numbers – that follows a defined pattern we can test against.
Known text is unstructured content, typically found in documents, where we know the source and want to protect that specific information. Examples are engineering plans, source code, corporate financials, and customer lists.
Images and binaries are non-text files such as music, video, photos, and compiled application code.
Conceptual text is information that doesn’t come from an authoritative source like a document repository but may contain certain keywords, phrases, or language patterns. This is pretty broad but some examples are insider trading, job seeking, and sexual harassment.
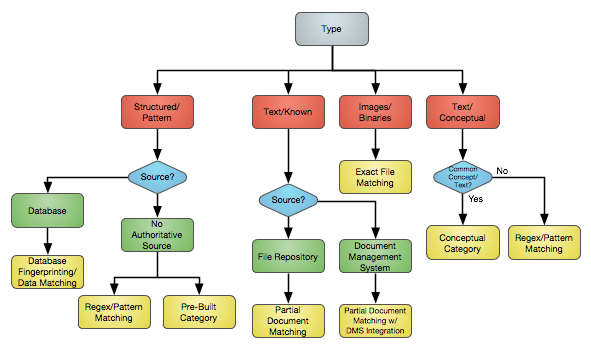
Match data types to required content analysis techniques
Using the flowchart below, determine required content analysis techniques based on data types and other environmental factors, such as the existence of authoritative sources. This chart doesn’t account for every possibility but is a good starting point and should define the high-level requirements for a majority of situations.
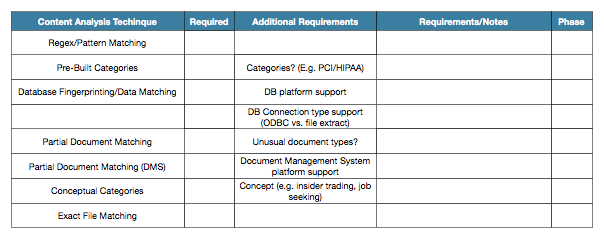
Determine additional requirements
Depending on the content analysis technique there may be additional requirements, such as support for specific database platforms and document management systems. If you are considering database fingerprinting, also determine whether you can work against live data in a production system, or will rely on data extracts (database dumps to reduce performance overhead on the production system).
Define rollout phases
While we haven’t yet defined formal project phases, you should have an idea early on whether a data protection requirement is immediate or something you can roll out later in the project. One reason for including this is that many DLP projects are initiated based on some sort of breach or compliance deficiency relating to only a single data type. This could lead to selecting a product based only on that requirement, which might entail problematic limitations down the road as you expand your deployment to protect other kinds of content.