Enterprise DevSecOps: Security Test Integration and Tooling
In this section we show you how to weave security into the fabric of your DevOps automation framework. We are going to address the questions “We want to integrate security testing into the development pipeline, and are going to start with static analysis. How do we do this?”, “We understand “shift left”, but are the tools effective?” and “What tools do you recommend we start with, and how do we integrate them?”. As DevOps encourages testing in all phases of development and deployment, we will discuss what a build pipeline looks like, and the tooling appropriate for stage. The security tests typically sit side by side with functional and regression tests your quality assurance teams has likely already deployed. And beyond those typical post-build testing points, you can include testing on a developer’s desktop prior to check-in, in the code repositories before and after builds, and in pre-deployment staging areas.
Build Process
During a few of the calls we had, several of the senior security executives did not know what constituted a build process. This is not a condemnation as many people in security have not participated in software production and delivery, so we want to outline the process and the terminology used by developers. If you’re already familiar with this, skip forward to ‘Building s Security Toolchain’.
Most of you reading this will be familiar with “nightly builds”, where all code checked in the previous day is compiled overnight. And you’re just as familiar with the morning ritual of sipping coffee while you read through the logs to see if the build failed and why. Most development teams have been doing this for a decade or more. The automated build is the first of many steps that companies go through on their way toward full automation of the processes that support code development. Over the last several years we have mashed our ‘foot to the floor’, leveraging more and more automation to accelerate the pace of software delivery.
The path to DevOps is typically taken in two phases: first with continuous integration, which manages the building and testing of code; then continuous deployment, which assembles the entire application stack into an executable environment. And at the same time, there are continuous improvements to all facets of the process, making it easier, faster and more reliable. It takes a lot of work to get here, and the scripts and templates used often take months just to build out the basics, and years to mature them into reliable software delivery infrastructure.
Continuous Integration
The essence of Continuous Integration (CI) is developers regularly check-in small iterative code advances. For most teams this involves many updates to a shared source code repository, and one or more builds each day. The key is smaller, simpler additions, where we can more easily and quickly find code defects. These are essentially Agile concepts, implemented in processes which drive code, rather than processes that drive people (such as scrums and sprints). The definition of CI has evolved over the last decade, but in a DevOps context CI implies that code is not only built and integrated with supporting libraries, but also automatically dispatched for testing. Additionally, DevOps CI implies that code modifications are not applied to branches, but directly into the main body of the code, reducing the complexity and integration nightmares that can plague development teams.
This sounds simple, but in practice it requires considerable supporting infrastructure. Builds must be fully scripted, and the build process occurs as code changes are made. With each successful build the application stack is bundled and passed along for testing. Test code is built before unit, functional, regression, and security testing, and checked into repositories and part of the automated process. Tests commence automatically whenever a new application bundle is available, but it means the new tests are applied with each new build as well. It also means that before tests can be launched test systems must be automatically provisioned, configured, and seeded with the necessary data. Automation scripts must provide monitoring for each part of the process, and communication of success or failure back to Development and Operations teams as events occur. The creation of the scripts and tools to make all this possible requires Operations, Testing and Development teams to work closely together.
The following graphic shows an automated build pipeline, including security test points, for containers. Again, this level of orchestration does not happen overnight, rather an evolutionary process that take months to establish the basics and years to mature. But that is the very essence of continuous improvement.
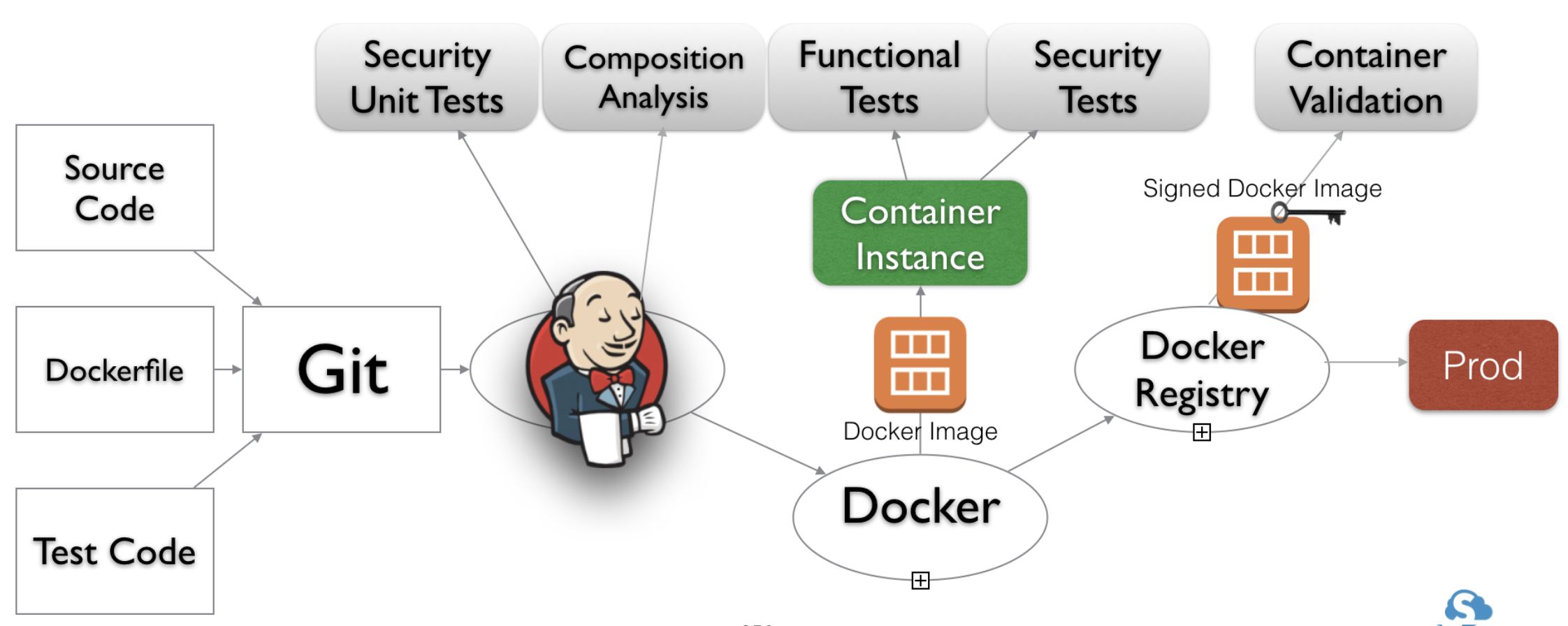
Continuous Deployment
Continuous Deployment looks very similar to CI, but focuses on the releasing software to end users rather than building it. It involves similar packaging, testing, and monitoring tasks, with some additional wrinkles. Upon a successful completion of a build cycle, the results feed the Continuous Deployment (CD) process. CD takes another giant step forward for automation and resiliency but automating the release management, provisioning and final configuration for the application stack, then launches the new application code.
When we talk about CD, there are two ways people embrace this concept. Some teams simply launch the new version of their application into an existing production environment. The CD process automates the application layer, but not the server, data or network layers. We find this common with on-premise applications and in private cloud deployments, and some public cloud deployments still use this model as well.
A large percentage of the security teams we spoke with are genuinely scared of Continuous Deployment. They state “How can you possibly allow code to go live without checks and oversight!”, missing the point that the code does not go live until all of the security tests have been passed. And some CI pipelines contain manual inspection points for some tests. In our experience, CD means more reliable and more secure releases. CD addresses dozens of issues that plague code deployment — particularly in the areas of error-prone manual changes, and discrepancies in revisions of supporting libraries between production and development. Once sufficient testing is in place, there should be no reason to mistrust CD.
Not all firms release code into production every day; in fact less than 10% of the firms we speak with truly release continually, but some notable companies like Netflix, Google and Etsy have automated releases once their tests have completed. But most firms (i.e. : those not in the content or retail verticals) do not have a good business need to release updates multiple times a day, so they don’t.
Managed / Blue-Green Deployments
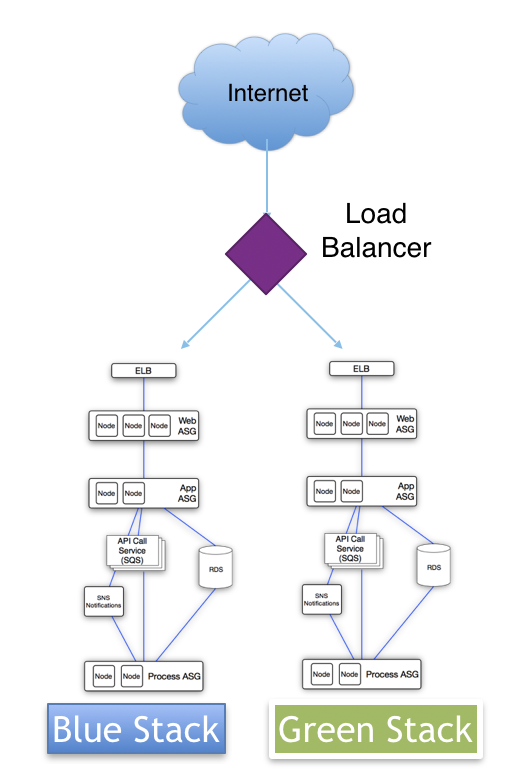
Most firms have a slower release cycle, often with a ‘go live’ cadence of every one to three sprints. We call these ‘managed releases’ as the execution and timing is manual, but most of the actions are automated. Plus these firms employ another very powerful technique: Automated infrastructure deployments. This is where you cycle the entire infrastructure stack along with the application. These types of deployments rely upon automating the environment the software runs in; this can be as simple as standing up a Kubernetes cluster, or leveraging Openshift to run Terraform templates into Google GCP, or launching an entire AWS environment via Cloudformation templates. The infrastructure and the application are all code, and so both are launched in tandem. This is becoming common in public cloud deployments.
But this method of release offers significant advantages and provides the foundation from what is called ‘Blue-Green’ or Red-Black deployment. Old and new code run side by side, looking close to mirror images, each on their own set of servers. While the old code (i.e.: Blue) continues to serve user requests, new code (i.e.: Green) is exercised only by select users or test harnesses. A rollout is a simple redirection at the load balancer level, and internal users and live customers can be slowly re-directed to the Green servers, essentially using them as testers for the new system. If the new code passes all required tests, the load balancer sends all traffic to the Green servers, the Blue servers are retired, and Green then becomes the new Blue. If errors are discovered, the load balancers are pointed back to the old ‘Blue’ code until a new patched version is available. This is essentially pre-release testing in production, and near instantaneous rollback in the even there are defects or security problems discovered.
Where to Test
Desktop Security Tests
Integrated Development Environments, or IDEs, are the norm for most developers. Visual Studio, Eclipse, IntelliJ and many more, some tailored to specific languages or environments. These desktop tools not only help with building code, but they integrate syntax checkers, runtimes, terminals, packages, and lots of other features to make building code easier. Commercial security vendors have plug-ins for the popular tools, usually providing a form of static analysis. Sometimes these tools are interactive, giving advice as code is written, while others check currently modified files on demand, before code is committed. There are even one or two that do not actually ‘plug in’ to the IDE, but work as a standalone tool and run prior to checkin. As the code scans are typically just the module or container that the developer is working on, code scans happen very quickly. And getting the security scans right at this stage lowers the likelihood that the build server will find and fail on security issues after code is checked in.
The development teams we have worked with that use these tools find them to be effective and deliver as promised. Many individual developers we speak with do no like many of these security plug ins as they find them noisy and distracting. We recommend the use of these desktop scanners when possible but recognize the cultural impediment to use, and caution that security teams may need to help change the culture and allow adoption to grow over time.
Code Repository Scanning
Source code management, configuration management databases, container registries and similar types of tools store code and help with management tasks like versioning, IAM and approval processes. From a security standpoint, several composition analysis vendors have integrated their products to check that open source versioning is correct and that the platforms in use do not contain known CVEs. Additional facilities to create digital fingerprints for known good version and other version control features are becoming more common.
Build Server Integration
Build servers build applications. Often comprised of multiple sources of in-house developed and open source code, it is common for many ‘artifacts’ to be used in the construction of an application. Build servers like Jenkins and Bamboo fortunately have the hooks needed to massage these artifacts, both before and after a build. This is commonly how testing is integrated into the build pipeline. Leveraging this capability will be central to your security test integration. Composition analysis, SAST and custom tests are commonly integrated at this stage.
Pre-release
For ‘code complete’ or systemic testing, where all of the parts of the application and the supporting application stack are assembled, a pre-production ‘staging area’ is setup to mimic the production environment and facilitate a full battery of tests. We are finding several trends of late, and pre-production testing is one of them. As public cloud resources allow for rapid elasticity and on-demand resource procurement, firms are spinning up test environments, running their QA and security tests, then shutting them back down again to reduce costs. In some cases this is used to do DAST testing that used to be performed in production. And in most cases this is the means for Blue-Green deployment model is leveraged to run many different types of testing on anew environment parallel to the existing production environment.
Building a Security Toolchain
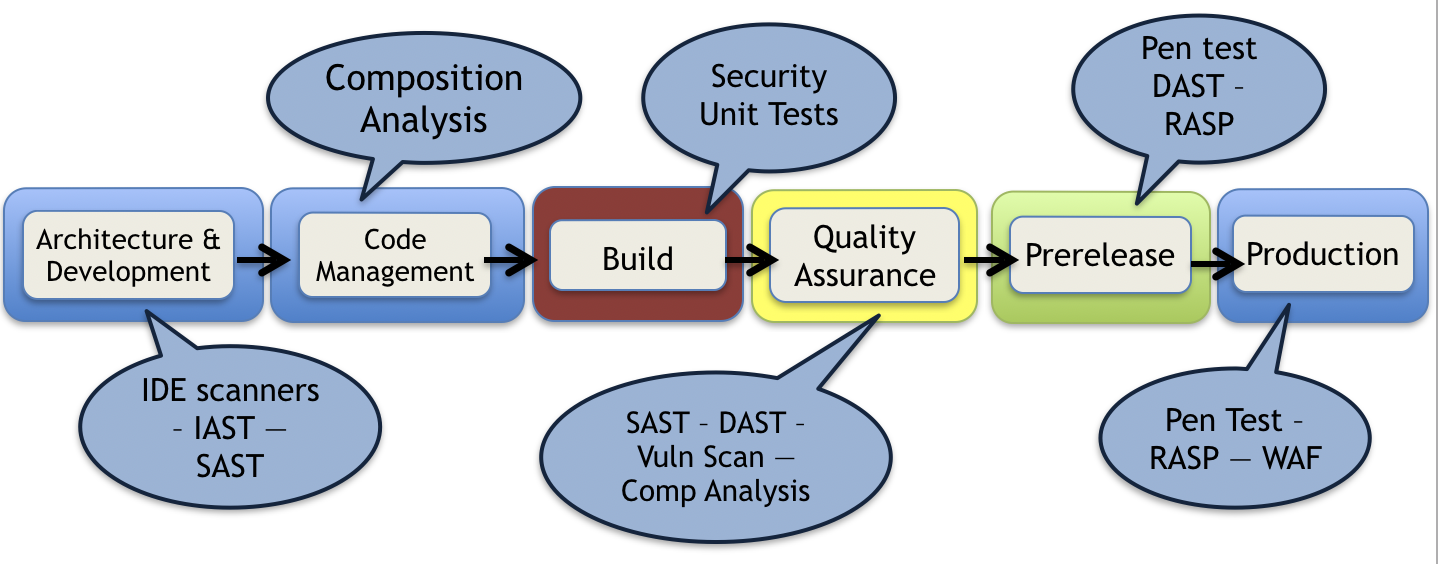
Static Analysis
Static Application Security Testing (SAST) examines all code — or runtime binaries — to support a thorough search for common vulnerabilities. These tools are highly effective at finding flaws, even in code that has been manually reviewed. You selection criteria will likely boil down to speed of scan, ease of integrations, readability of the results and lack of false positives. Most of these platforms have gotten much better at providing analysis that is useful for developers, not just security geeks. And many of the products are being updated to offer full functionality via APIs or build scripts. If you have a choice, select tools with APIs for integration into the DevOps process, and which don’t require “code complete”. We have seen a slight reduction in use of these tests, as they often take hours or days to run — in a DevOps environment that can prevent them from running inline as a gate to certification or deployment. As we mentioned in the above under ‘Other’, most teams are adjusting to support out-of-band — or what we are calling ‘Parallelized’ — testing for static analysis. We highly recommend keeping SAST testing inline if possible, and focus on new sections of code to reduce runtime.
Dynamic Analysis
Rather than scanning code or binaries like SAST, Dynamic Application Security Testing (DAST) dynamically ‘crawls’ through an application’s interface, testing how it reacts to various inputs. These scanners cannot see what’s going on behind the scenes, but they offer valuable insight into how code behaves, and can flush out errors which other tests may not see in dynamic code paths. The good news is they tend to have low rates of false positives. These tests are typically run against fully built applications, and can be destructive, so the tools often offer settings to run more aggressively in test environments. And like SAST may require some time to fully scan code, so in line tests that gate a release are often run against new code only, and full application sweeps are run ‘in parallel’.
Composition and Vulnerability Analysis
Composition Analysis tools check versions of open source libraries to assess open source risk, both with security vulnerabilities and potential licensing issues. Things like Heartbleed, misconfigured databases, and Struts vulnerabilities may not be part of your application testing at all, but they all critical application stack vulnerabilities. Some people equate vulnerability testing with DAST, but there are other ways to identify vulnerabilities. In fact there are several kinds of vulnerability scans; some look settings like platform configuration, patch levels or application composition to detect known vulnerabilities. Make sure you broaden you scans to include your application, your application stack, and the open source platforms that support it.
Manual Code Review
Some organizations find it more than a bit scary to fully automate deployment, so they want a human to review changes before new code goes live — we understand. But there are very good security reasons for review as well. In an environment as automation-centric as DevOps, it may seem antithetical to use or endorse manual code reviews or security inspection, but manual review is still highly desirable. Some types of vulnerabilities are not part of scanning tools. Manual reviews often catch obvious stuff that tests miss, and developers can miss on their first (only) pass. And developers’ ability to write security unit tests varies. Whether through developer error or reviewer skill, people writing tests miss stuff which manual inspections catch. Your tool belt should include manual code inspection — at least periodic spot checks of new code or things like Dockerfile which are often omitted from scans.
Runtime Protection
Many firms still leverage Web Application Firewalls, but usage is on the decline. We are seeing increased usage of Runtime Application Self Protection in production to augment logging and protection efforts. These platforms instrument code, provide runtime protection, and in some cases identify which lines of application code are vulnerable.
DevOps requires you have better monitoring in order to collect metrics so you can make adjustments based upon operational data. To validate that the new application deployments are functioning, monitoring and instrumentation are more commonly built in. In some cases these are custom packages and ELK stacks, in others it is as simple as leaving logging and ‘debug’ style statements – traditionally used during the development phase – turned on in production. This is more prominent in public cloud IaaS, where you are fully responsible for data and application security where native logs do not provide adequate visibility.
Security Unit Tests
Unit testing is where you check small sub-components or fragments (‘units’) of an application. These tests are written by programmers as they develop new functions, and commonly run by developers prior to code check-in, but possibly within the build pipeline as well. These tests are intended to be long-lived, checked into the source repository along with new code, and run by every subsequent developers who contributes to that code module. For security these may straightforward — such as SQL injection against a web form — or more sophisticated attacks specific to the function under test, such as business logic attacks — all to ensure that each new bit of code correctly reflects the developers’ intent. Every unit test focuses on specific pieces of code — not systems or transactions. Unit tests attempt to catch errors very early in the process, per Deming’s assertion that the earlier flaws are identified, the less expensive they are to fix. In building out unit tests you will need to support developer infrastructure to embody your tests, and also to encourage the team to take testing seriously enough to build good tests. Having multiple team member contributes to the same code, each writing unit tests, helps identify weaknesses a single programmer might not consider.
Security Regression Tests
A regression test verifies that recently changed code still functions as intended. In a security context this is particularly important to ensure that vulnerabilities remain fixed. DevOps regression tests are commonly run parallel to functional tests — after the code stack is built out. And in some cases this may need to be in a dedicated environment, where security testing can be destructive and cause side effects that are unacceptable in production servers with real customer data. Virtualization and cloud infrastructure are leveraged to expedite instantiation of new test environments. The tests themselves are typically home-built test cases to exploit previously discovered vulnerabilities, either as unit or systemic tests. The author uses these types of tests to ensure that credentials like passwords and certificates are not included in files, and that infrastructure does not allow port 22 or 3389 access.
Chaos Engineering
Chaos engineering is where random failures are introduced, usually in the production environment, to see how application environments handle adverse conditions. Firms like Netflix has pioneered efforts in this field in order to force their development teams to understand common failure types, and build graceful failure and recovery into their code. From a security standpoint, if an attacker can force an application into a bad state, they can often coerce the application to perform tasks it was not intended to take. Building ruggedness into the code improves reliability and security.
Fuzzing
At its simplest fuzz testing is essentially throwing lots of random garbage at applications, seeing whether any particular (type of) garbage causes errors. Many dynamic scanning vendors will tell you they provide fuzzing. They don’t. Go to any security conference — Black Hat, DefCon, RSA, or B-Sides — and you will see that most security researchers prefer fuzzing to find vulnerable code. It has become essential for identifying misbehaving code which may be exploitable. Over the last 10 years, with Agile development processes and even more with DevOps, we have a steady decline in use of fuzz testing by development and QA teams. This is because it’s slow; running through a large test body of possible malicious inputs takes substantial time. This is a little less of an issue with web applications because attackers can’t throw everything at the code, but much more problematic for applications delivered to users (including mobile apps, desktop applications, and automotive systems). We almost excluded this section as it is rare to see true fuzz testing in use, but for critical systems, periodic – and out of band – fuzz testing should be part of your security testing efforts.
Risk and Exposure Analysis
Integrating security findings from application scans into bug tracking systems is not that difficult technically. Most products offer it as a built-in feature. The hard part is figuring out what to do with the data once obtained. Is a discovered security vulnerability a real issue? If it is not a false positive, can the vulnerability be exploited? What is its criticality and priority, relative to everything else? And if we choose to address it, how should we deal with it from a set of options (unit test, patch, RASP)?
Another aspect to consider is this information distributed without overloading stakeholders. With DevOps you need to close the loop on issues within infrastructure, security testing as well as code. And Dev and Ops offer different possible solutions to most vulnerabilities, so the people managing security need to include operations teams as well. Patching, code changes, blocking, and functional whitelisting are all options for closing security gaps; so you’ll need both Dev and Ops to weigh the tradeoffs.